

Miroservices, REST, API's... not too sure if I could have fit more buzzwords into a blog post title, but I do know one thing. All these buzzwords have been used to stoke doubt in hearts of developers, architects and the C-Suite that if you're not "doing" microservices, don't have an API for everything, and you're not "doing" REST, you're doing something wrong. And you're most definitely doing something wrong if you're not doing everything over HTTP.
So, I'm going to just drop this bomb now: Microservices is not REST over HTTP.
In this blog post, I'll illustrate the harm that service-to-service communication over HTTP can cause in a microservices architecture, and to offer an alternative approach to sharing data in a distributed system.
A Tale of Two API Usages
Before showing you how REST API's can be mis-used, let's add a little positivity here and show a good example of how to use API's in a microservices architecture.
API's for Composite UI's
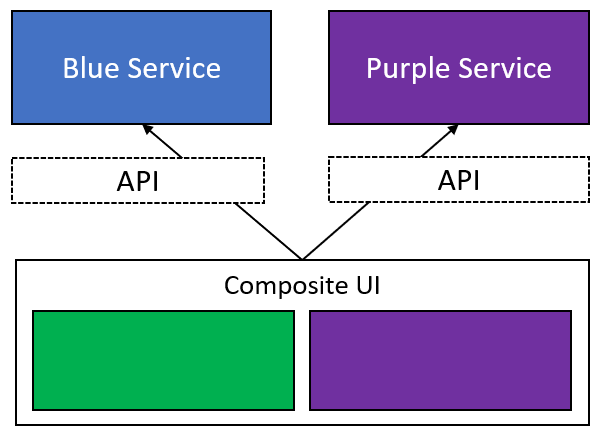
In this diagram, we have two microservices and we have a Composite UI. In order for the UI to compose together a full picture of data for the user, those pieces of the UI reach out to each service, and retrieve what it needs to show.
So what's wrong here? Nothing!
This is a completely normal and expected API usage. Since most web development these days is taking place on client-side frameworks like Angular, Vue and React (and hopefully, much more client-side Blazor in the near future), there's an unwritten expectation that API's will be built to enable front-end code to read and write data to the application.
These API's become very important contracts and expose all the functionality of the back-end systems to font-end callers. Understandably, a lot of time is spent on designing and implementing them; making them clear, getting them right, and passing back exactly what the front-end needs to do its job.
The API's are critical to the success of the project.
API's for Service-to-Service Communication
With so much work going into perfecting these API's, the allure of leveraging the work already done is significant when back-end developers find themselves in the following situation.
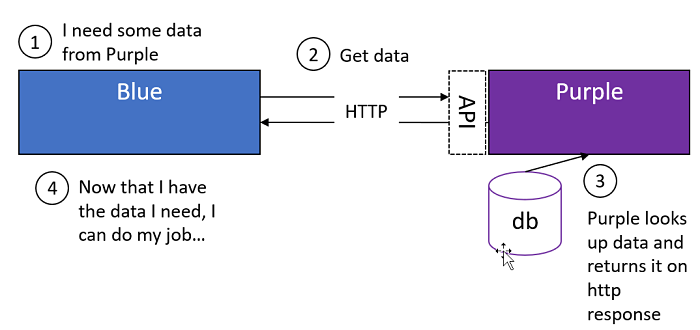
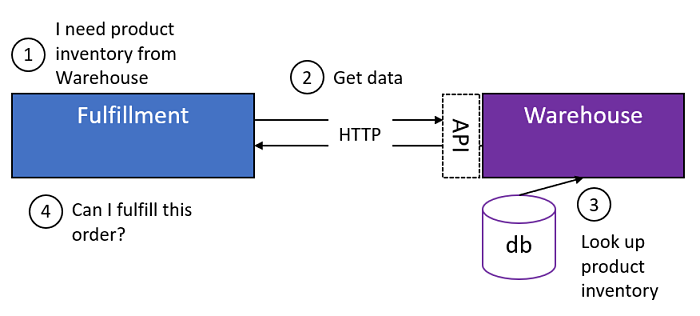
The Blue Service is performing an operation that requires it to reach out to the Purple Service to retrieve information in order for it to do its job.
So what's the problem? It's using an HTTP call to do it. HTTP is a synchronous, blocking protocol that usually requires the caller to wait for a response. Sure, there are optimizations in .NET like async/await, but these merely allow the caller to "multi-task" after the request has been made. Using async/await doesn't change the fact that you're still waiting for a response.
Why is this bad?
For every command Blue is processing, it needs to call to Purple so it can do its job. Because the call is blocking, network unreliability, broker unavailability, Purple's performance or Purple's unavailability can cascade timeouts and exceptions to Blue. These errors could in turn, make Blue unresponsive, and so on and so on until the whole system is brought down. One big, blocking HTTP invocation chain.
Does this sound like service autonomy? Nope! It sounds like coupling. And in this case, it's a specific type of coupling called temporal coupling.
Let's take a step back. Why does Blue need to keep getting data from Purple to do its job? The Tenants of SOA tell us that each service needs to be autonomous. What this means is both the behavior and the data that the service needs to do its job should be located in that service. If Blue is reaching out to Purple to get data is needs to do its job, then clearly, Blue is not autonomous, and Purple potentially is not autonomous either.
More importantly, what kind of data is Blue allowed to get from the Purple? In many cases, it's data that should be encapsulated by Purple. So, when Purple freely gives this data to Blue, logical coupling is created.
Now that we've established the temporal, and possible logical coupling introduced by using HTTP for service-to-service communication in a microservices architecture is bad, how can we fix it?
Even a distributed system needs to share some data across services. No system (that is useful), works in complete isolation. There are times when one service will need a subset of data from another service in order for it to do it's job.
Instead of relying on service-to-service communication over HTTP, we can use messaging instead.
Detour: What About Caching?
One of the first responses I usually get to the "let's use messaging" approach is "we could fix this by caching the data".
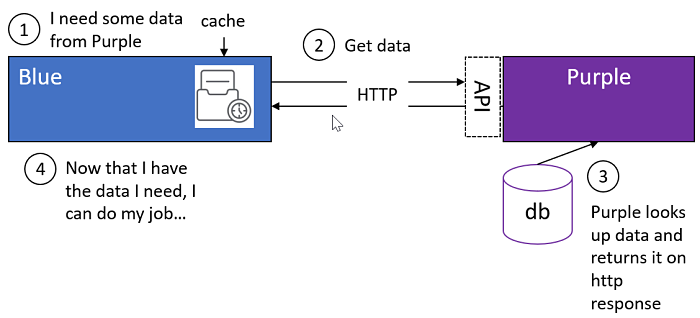
How long do you cache data? How do you handle cache invalidation? Can the invalidation be based on load? Do I need a distributed cache? Going down this road can to introduce complexities in the implementation. Did I mention cache invalidation?
The irony here is those who want to avoid eventual consistency by insisting on getting data in "real-time" via a blocking HTTP call end up getting eventual consistency anyhow, in the form of a cache. Yes, caching is a form of eventual consistency. Why? Because at any point, the data that Blue is working with (retrieved and cached from Purple) could be stale, which means that data is eventually consistent.
Okay, back to messaging!
Exploring Messaging
Now that we've addressed the caching concern, let's explore what a messaging-based implementation for sharing data between services could look like.
How do we do that? Flip the problem on it's head.
Instead of Blue reaching out to Purple to get data, switch to a pub/sub model where Purple publishes events that Blue can subscribe to.
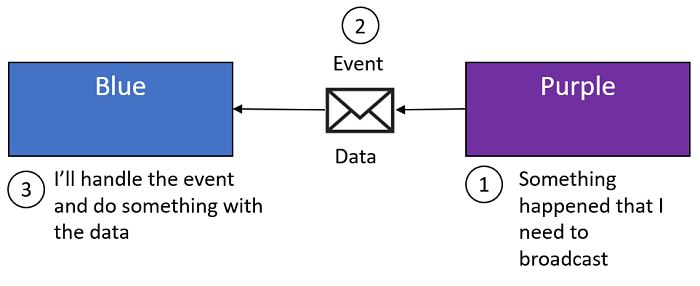
Before you run off and implement this approach, there are a couple important points to consider.
First, the data that Purple chooses to share on that event should be data that represents stable business abstractions. Purple isn't just sharing data with Blue, it's sharing data with any other boundary that subscribes to that event. Once that event is published, the data on that event is "out there", and any subscribing service will be coupled to the data on that message. A good guiding principal here is to share as little data as possible to get the job done.
Second, taking this approach will introduce eventual consistency. It's entirely possible that messages being published by Purple are delayed because network conditions, transient errors, broker unavailability, or The Other Million Things that Will Go Wrong in Production. Because we have no control over those conditions, our code, and more importantly, the business itself, needs to be aware that Blue could do something it shouldn't because the data on which it is acting is stale. This inconsistent state can be managed by Compensating Actions, but that is another blog post for another day.
Now that we've built up context, and have a "lay of the land", let's dive into a more specific example rooted in the Shipping domain.
The Shipping Domain
In our Shipping domain, we'll have two services, Fulfillment and Warehouse.
- Fulfillment is responsible for fulfilling an order. For the sake of simplicity, let's assume each order has one product for now.
- Warehouse is the source of truth for how much stock of each product is available from which to fulfill an order.
With those basic definitions in place, let's take a look at how we can use messaging to share data from Warehouse with Shipping so Shipping can make a determination on whether or it can fulfill an order based on Warehouse inventory.
Don't Call Me, I'll Call You
Instead of Fulfillment reaching out to Warehouse to get the available inventory of a product so it can determine if it can fulfill the order
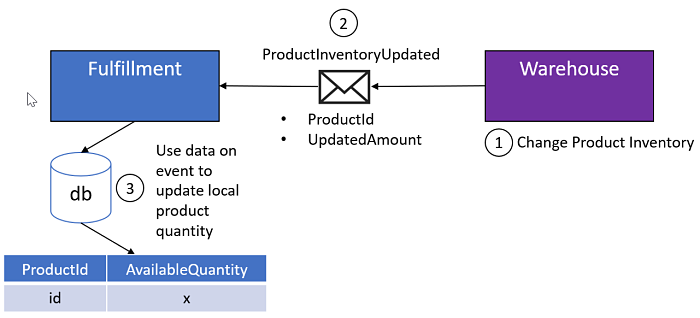
We're going to look to Warehouse to publish events to broadcast inventory changes at the product level. For this example we'll make the event very coarse and call it ProductInventoryUpdated.
public class ProductInventoryUpdated
{
public Guid ProductId { get; set; }
public int UpdatedAmount { get; set;}
}
UpdatedAmount could be a positive number (product was replenished via a shipment, product was restocked because of a return, etc.) or a negative number (orders are being fulfilled, product recalls, etc.). UpdatedAmount is a delta.
Fulfillment will subscribe to ProductInventoryUpdated. When Fulfillment handles the event it will read the last available quantity for the product id on the message from its local database, apply the delta to calculate the new available quantity and update the available quantity back to its local database.
What have we gained by taking this approach?
- eliminated the temporal coupling between the services
- enabled an asynchronous "fire-and-forget" approach for Warehouse to broadcast inventory updates via pub/sub.
- localized data to Fulfillment it needs to do its job
All without blocking HTTP requests. Here's an example of what this approach could look like.
ProductInventoryUpdated only contains only stable business abstractions; the id of the product and the delta of the inventory change.
I've mentioned stable business abstractions a couple times now and I've given examples of what type of data qualifies. What about an example of data that is not a stable business abstraction (data that shouldn't be shared)?
In this case, it could be data like product name, sku, bin # (where the product is located in the warehouse)... anything that Warehouse needs to do its job. That data and the behavior used to calculate the delta should remain properly encapsulated in the Warehouse service.
Refactoring from Delta to Available Quantity
So, we have a really good design, but there is room to make it better! Why are we making Fulfillment calculate anything? Right now, it's up to Warehouse to publish a delta of a product inventory adjustment, but why? Warehouse knows the available quantity, so why can't it just publish that?
Let's try it on for size:
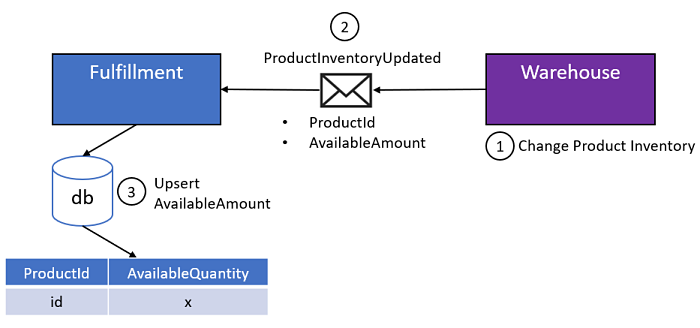
All Fulfillment has to do now is handle the event, and upsert the AvailableAmount for the matching product id in its local datastore. No calculations, just upsert and done.
Messaging Is Not Magic
At the end on the day, a message is nothing but a contract. Just like API's need to expose contracts to callers, messages themselves are contracts shared between a sender and a receiver(s). Contracts still need a versioning strategy and should be very opinionated about what data they share and with whom they share it.
So if you plan to expose all of the data contained in Warehouse on a message, expect the same coupling problems you had when you did it via a contract on an API. Although the delivery mechanisms are different, logically, the same mistake is being made, and your results will be the same... a gigantic, coupled mess.
In Closing
In this post I presented a viable alternative to using HTTP for service-to-service communication in a microservices architecture. Using pub/sub is a great way to start removing temporal coupling between your microservices as well as get started with messaging.
Like any approach, don't just rip through your code-base and do this.

Look for chained HTTP calls across multiple services, especially those that are causing performance issues or experiencing unreliability at scale. Look through your code and identify services that are over-reliant on data from other services and see if there are opportunities to either consolidate them or use messaging to decouple them.
Brokers offer a great entry point for low-ceremony pub/sub functionality. RabbitMQ allows you to work with Topics, which align with the pub/sub model. Azure Service Bus is also a great candidate in this space, with other goodies baked in like message de-duplication, batching, transactions and other service-bus-like functionality.
For frameworks supporting pub/sub semantics via an API, check out CAP, an event bus. For pub/sub semantics plus enterprise grade strength, check out NServiceBus or ReBus.