

Although we’ve been using it for over three years at my job developers are still incorrectly using Entity Framework’s .AddOrUpdate(). I’ve also seen incorrect usages of in open source projects as well. Maybe it’s the way Microsoft named it, but a developer with little background in Entity Framework as well as Entity Framework Migrations could look at that name and take it literally to mean “if the record does not exist, insert it, if it does exist, update it”.
Although that is what AddOrUpdate does, it’s the “Update” part of AddOrUpdate that is misunderstood. If you do not supply a fully populated entity to AddOrUpdate<T> via an earlier read you will end up losing data, or said another way:
unless the add or update is a 1:1 with the table you’re updating in the database, you will lose data
This post will take a look at the existing .AddOrUpdate implementation in Entity Framework 6.x, and then look to see how Entity Framework 7 (Core) is attempting to handle the concept of “add or update”.
EF 6 AddOrUpdate
If you look at the main Entity Framework 6 code that does things like Add and Remove, you’ll note these live in the System.Data.Entity namespace, but there is no AddOrUpdate there. That’s because the AddOrUpdate method actually lives in the [DbSetMigrationsExtension](https://github.com/aspnet/EntityFramework6/blob/602bc779baa598fecf6f1ad9b94d76e8d30a9c15/src/EntityFramework/Migrations/DbSetMigrationsExtensions.cs) class, because it’s intended usage is for EF Migrations. That being said, that does not mean you can’t use it as part of writing EF code, but it does mean you have to understand it before doing so.
Let’s take a look at an example of using AddOrUpdate incorrectly, and what it could mean for your data.
EF6: Naive Usage of AddOrUpdate
Given a Customer class:
public class Customer
{
public int Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set;}
public string Address { get; set;}
public string City {get; set; }
public string State { get; set;}
public string Zip { get; set; }
}
we have one Customer in our d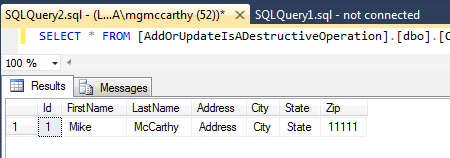
](http://www.michaelgmccarthy.com/content/images/2016/08/existingcustomer.png)
Let’s say we have an MVC action method that returns a CustomerViewModel:
public class CustomerViewModel
{
public int Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set;}
}
[HttpGet]
public async Task<IActionResult> Edit(int customerId)
{
var customer = context.Customer.Single(x => x.Id == customerId);
return View(new CustomerViewModel { Id = customer.Id, FirstName = customer.FirstName,
LastName = customer.LastName });
}
Back in the UI, we only allow the editing of FirstName and LastName for the customer (basically, the CustomerViewModel is optimized for this). Then we post back to our controller:
[HttpPost]
public async Task<IActionResult> Edit(CustomerViewModel customerViewModel)
{
var customer = new Customer { Id = customerViewModel.Id,
FirstName = customerViewModel.FirstName, LastName = customerViewModel.LastName };
context.AddOrUpdate(customer)
context.SaveChangesAsync();
return RedirectToAction(nameof(Index));
}
NOTE: we’re not querying the database first here to get the Customer, because AddOrUpdate already queries the database for us. Also, keep in mind that this is an naive example of showing how AddOrUpdate’s API can be used incorrectly.
In the Edit POST ActionMethod, we create a Customer, map the values from the ViewModel, then call context.AddOrUpdate. Let’s take a look at the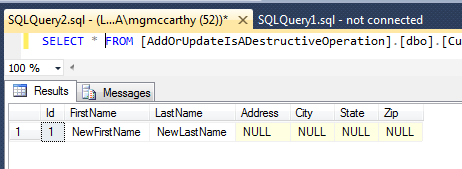 ](http://www.michaelgmccarthy.com/content/images/2016/08/addorupdatelostourdata.png)
](http://www.michaelgmccarthy.com/content/images/2016/08/addorupdatelostourdata.png)
This is not at all what was expected! Why have we lost the data that was not involved as part of the update when we provided an Id of a known Customer to the customer we passed to AddOrUpdate?
It’s because Entity Framework does not magically figure out which properties have changed vs. which properties have not changed, it takes the entity, and if it exists, enters the entity into the database as it’s currently populated. If the entity does not exist, it inserts it into the database.
It’s true in the Edit POST ActionMethod we could first execute a read (select) to get the customer from persistence, then invoke AddOrUpdate on that customer, but like I said earlier, AddOrUpdate already does a read operation as part of its job, so writing that code is essentially round-tripping to the database for the same information twice.
[HttpGet]
public async Task<IActionResult> Edit(CustomerViewModel customerViewModel)
{
//VERY BAD, DON’T DO THIS!!!
var customer = context.Customers.Single(x => x.Id == customerViewModel.Id);
customer.FirstName = customerViewModel.FirstName;
customer.LastName = customerViewModel.LastName;
context.AddOrUpdate(customer)
context.SaveChangesAsync();
return RedirectToAction(nameof(Index));
}
This approach is incorrect and should be considered an anti-pattern.
How Do I Fix It?
The easiest way to stop this behavior, is to get rid of the CustomerViewModel class and work with the Customer entity class directly. Using this approach:
[HttpGet]
public async Task<IActionResult> Edit(int customerId)
{
var customer = context.Customer.Single(x => x.Id == customerId);
return View(customer);
}
In our UI, we’re still allowing editing of FirstName and LastName, but carry the rest of the customer’s values through hidden fields in the razor view.
The POST method will take a Customer as a parameter to the method and since this Customer is the same Customer that was originally provided by the read in the GET method, it’s safe to pass this to AddOrUpdate as all the properties were are populated from the the initial read.
[HttpPost]
public async <IActionResult> Edit(Customer customer)
{
context.AddOrUpdate(customer)
context.SaveChangesAsync();
return RedirectToAction(nameof(Index));
}
We’re obviously making assumptions about optimistic concurrency here, but taking that out of the picture, we’ve simplified the Get and Post action methods by just working directly with Customer instead of mapping between a ViewModel and a Customer.
Returning the Customer to the view and using hidden fields to store the values we don’t want to allow to be editable, then posting back to the Edit action method allows us to supply the Customer along with the fields that we allowed someone to change (FirstName and LastName) to AddOrUpdate and let it do the work for us. If you are working on a UI that does not require any .Join on .Include statements, then just passing back the entity itself is a very simple thing to do, and results in less code written and no mapping code to write.
If you need to use a ViewModel (and the only time you should use one is when you are working on the read side of multiple entities), then don’t use AddOrUpdate. You’ll need to handle checking for the existence of one or more entities in the database (read), and then deciding if you’ll insert or update those entities based on what comes back from the read.
EF 7/Core: AddOrUpdate Is Missing, Now What? (hint: write your own)
So far, it looks like there are no plans for EF 7/Core to add AddOrUpdate functionality. Reading here and here, it looks like people are asking for it, but it’s still unknown whether or not it will be included.
I regularly contribute to an open source project called AllReady that just went through the RTM upgrade of .NET Core. This was an interesting upgrade in the fact that is inherently changed the way Entity Framework worked under the covers. For a full breakdown of the difference, and the change the project had to make, check out this excellent write up by Steven Gordon (another regular contributor): Exploring Entity Framework Core 1.0.0 RTM Changes.
Since there is no AddOrUpdate for EF 7/Core, Shawn Wildermuth wrote an AddOrUpdate implementation for AllReady as he lead the charge on upgrading the project to RTM:
public static class ContextExtensions
{
public static void AddOrUpdate(this DbContext ctx, object entity)
{
var entry = ctx.Entry(entity);
switch (entry.State)
{
case EntityState.Detached:
ctx.Add(entity);
break;
case EntityState.Modified:
ctx.Update(entity);
break;
case EntityState.Added:
ctx.Add(entity);
break;
case EntityState.Unchanged:
//item already in db no need to do anything
break;
default:
throw new ArgumentOutOfRangeException();
}
}
}
Note the usage of EntityState, and how that is used a switching mechanism for which method should be called from DbContext.
Just to clarify, using this extension method still forces the consuming code to query for the existence of an entity with the same id first, then proceed from there. This does not function like EF 6’s AddOrUpdate.
Here is an example of code using the AddOrUpdate extension method:
var customer = context.Customers.SingleOrDefault(c => c.Id == customerId)
?? new Customer();
//update some properties
context.AddOrUpdate(customer);
context.SaveChanges();
We’re using the null-coalescing operator to create a new Customer for us if we don’t find an existing Customer in the database for the given customerId. We then delegate to AddOrUpdate to figure out whether to add or update this entity.
In Conclusion
We’ve done a walk through of two AddOrUpdate implementations based on EF 6 and EF 7 in this blog post.
- EF 6’s AddOrUpdate is an “all or nothing” operation that is destructive and needs to be understood in order to use correctly
- EF 7 does not have AddOrUpdate yet, but there are existing Issue’s opened on GitHub to include it in EF 7. We briefly examined a hand-rolled AddOrUpdate implementation for EF 7 based on EntityState
Long story short, AddOrUdpate is incredibly useful, especially when working directly with an Entity Framework tracked model, but if you don’t know what you’re doing, AddOrUpdate can get you in a lot of trouble. Use GitHub, read the source code and understand the ramifications of AddOrUpdate before beginning to use it.