

Photo by Davide Baraldi from Pexels
NServiceBus retries.
We can always rely on them to retry failed messages for us. We have FLR’s, SLR’s, and finally, the error queue. Retries, especially for things like outbound web service integrations, are a life saver:
- web service is down? retries handles that.
- network is down? retries handles that.
- wrong credentials on the request? eventually, retries can handle that as well.
All of these are great examples of the durability of NServiceBus when one or more of the Fallacies of Distributed Computing rears its ugly head when our code is running in production.
But what happens when message retries can’t fix things?
Poison Messages
When messages fail and end up in the error queue, we have tools like ServicePulse and ServiceInsight to help us figure out what went wrong and to retry failed messages for us.
But what if a retry can’t fix a message failure?
Messages that cannot be fixed by retries are referred to as “poison messages” (which have been written about extensively here, here and here). Because NServiceBus messages are durable, which means the data written to the underlying transport (we use MSMQ) is immutable, we can’t open up an MSMQ message, and change the data in the body to meet our needs and resend the message. We need to somehow regenerate the message with the correct data and run it through the NServiceBus pipeline again.
This approach sounds fine, until you’re faced with the fact that the message generated was a result of an event being published in the system. If this in the case, you most likely can’t re-run the entire use case that resulted in that event being published because of the possible side-effects that re-publishing that event could have in your system. Remember, events can have more than one subscriber, and most likely, the event that was published came from a command handler, which means that command handler would also need to be re-run.
Even if we COULD re-run the use case that resulted in the event being published so our handler could have another crack at building the data it needed correctly, the data on the message would be the data of the system’s current state, not the “snapshot” of the data we need from when the message originally failed.
So, how can we handle web service integrations that have failed when the failure is a direct result of the wrong data sent to the web service, and that data was generated by handling an event?
Answer: take NServiceBus retries out of the mix altogether and handle these poison messages ourselves.
A Little Background
For this web service integration, our system was responsible for keeping track of and incrementing an integer that was being used as a primary key in the XML being sent to the web service. This primary key was used by the web service on the back-end to facilitate a database insert into a system along with the other data sent on the message. This primary key was the bad data causing the web service call to fail.
So why did a “primary key” we had full control over fail on the web service’s system? The value we were providing as a primary key was not always guaranteed to be “available” on the web service’s back-end. Although the web service’s API and documentation both said this was a primary key, we were obviously NOT working with a primary key. In other words, the primary key was already taken.
There were different ways these primary keys could already be taken as a result of some user actions done on the web service’s software side. The user action in question usually being a mistake or a mis-configuration setting up the system. So when we sent our message, the primary key we were told “we have control over” was already used, and hence, a poison message was born.
These are the high level steps in the system that resulted in the XML being sent to the web service. We had two endpoints powering the integration, a “read” and a “send” endpoint.
- the “read” endpoint’s handlers: - subscribed to business-related events the integration was responsible for generating web service requests for.
- made read calls to our transactional database to get the data it needed to build a command to send to the integration’s “send” endpoint.
- the “send” endpoint, using the data on the command built by the read endpoint: - built the XML for different message types we needed to send to the web service
- invoked the call to the web service passing the generated XML in the body of the web service call
When the “send” endpoint received an error back from the web service, it would retry the failed message (which could never succeed because of the bad primary key value in the XML), and that message would inevitably end up in the error queue.
Here 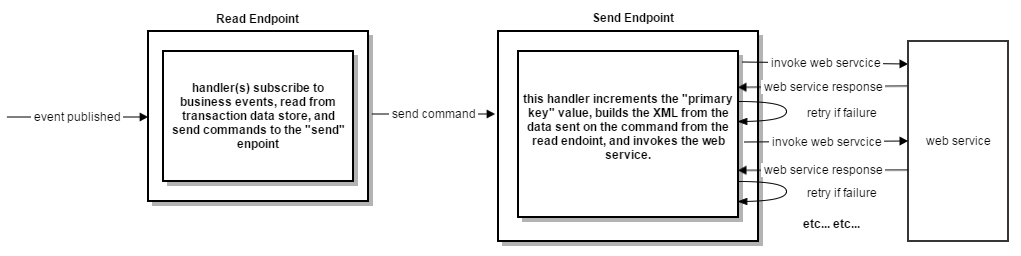 ](GHOST_URL/content/images/2015/07/edcdiagrambefore_edited2.png)
](GHOST_URL/content/images/2015/07/edcdiagrambefore_edited2.png)
We Can Fix This
At first, I thought, “we can fix this”. We’ll just check the returned data from the web service failure, see what the next available primary key is, rebuild the XML, and re-call the web service with the new primary key.
Unfortunately, the returned message did not contain ANY information about the primary key value in the response; not the highest taken primary key, not the next available primary key, etc…. If the returned message DID contain the highest used primary key value, we could have incremented the value, updated the data in the XML, and resent the message to the web service (although, this would still not guarantee 100% success).
Okay, not problem I thought. Let’s just take the primary key at the point it fails, auto-increment the primary key value and resend the message with the new primary key value until it succeeds. However, we could not take this approach because of limitations imposed on us by our domain by means of regulatory rules for this sort of operation.
So, it appeared there was no way for us to fix this message automatically within the NServiceBus retry process.
In the previous section I had mentioned taking NServiceBus retries out of the mix altogether and handling these poison messages ourselves. Here’s how we did it.
We Don’t Need No Stinkin’ NServiceBus Retries!
We knew we couldn’t auto-increment the primary key and keep re-sending to the web service until it succeeded because of the regulatory rules imposed on us via our domain. We needed a way to capture and fix these poison messages ourselves. We needed to:
- disable message retries on the send endpoint
- track the failed messages ourselves in some type of persistence
- allow the user to see what message(s) failed and the reason they failed
- allow the user to change the data on the XML that would allow the message(s) to succeed (preferably, without having them to resort to opening up XML in notepad and making the change by hand)
- allow the user to resend the message(s)
Disabling Retries on the Send Endpoint
We disabled SecondLevelRetries on the send endpoint by adding this class to the endpoint.
class DisableFeatures : INeedInitialization
{
public void Init()
{
Configure.Features.Disable<SecondLevelRetries>();
}
}
this class hooks into the INeedInitialization interface and uses configuration to Disable
Next, we removed these two lines from our app.config:
<section name="SecondLevelRetriesConfig" type="NServiceBus.Config.SecondLevelRetriesConfig, NServiceBus.Core" />
<SecondLevelRetriesConfig TimeIncrease="" />
Adding the DisableFeatures class and removing those two lines from our app.config disabled Second Level Retries on the endpoint.
But about the FLR’s? Find the TransportConfig line in your app.config file, and set MaxRetries equal to zero.
<TransportConfig MaxRetries="0" MaximumConcurrencyLevel="8" />
We’re done. The send endpoint will no longer use NServiceBus retries.
Handling Errors From the Web Service Invocation
Now that retries have been disabled, we need to step in and take a look at the response we’re getting back from the web service invocation. The web service returned data to the handler that synchronously invoked it, and that data contained an HttpStatusCode. If the HttpStatusCode is NOT equal to 200, we send MarkMessageAsFailed.
if (result.HttpStatusCode != 200)
{
bus.Send(new MarkMessageAsFailed
{
FailedMessage = new FailedMessage
{
MessageId = message.MessageId,
Message = result.Message,
HttpStatusCode = result.HttpStatusCode
}
});
}
When we handle MarkMessageAsFailed, we insert a new FailedMessage entity into the database. This entity has information on it about the failed web service call:
public class FailedMessage
{
[Key]
public Guid MessageId { get; set; }
public int HttpStatusCode { get; set; }
public string Message { get; set; }
public string Response { get; set; }
public string MessageType { get; set; }
public DateTime DateTimeUtc { get; set; }
}
Moving Towards a Functional UI
We can power a dashboard-style UI that will allow a user who is responsible for fixing these failed messages to s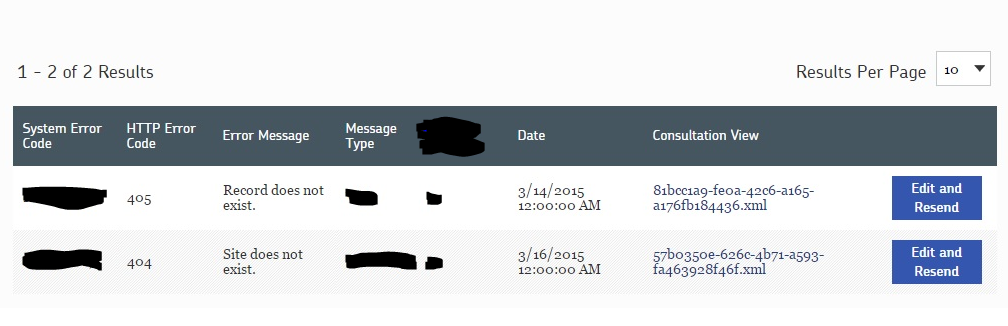 ](GHOST_URL/content/images/2015/07/failedmessagesdashboard.png)
](GHOST_URL/content/images/2015/07/failedmessagesdashboard.png)
Here we see the name of the XML file (in the “Consultation View” column) written to disk that represents the data that was sent to the web service that failed. The XML file name is rendered as a link. Clicking on the link allows the user to open the XML in a new browser window to visually inspect it. For someone who understands the domain, they’ll be able to eyeball the XML and most likely be able to make an educated guess about what data needs to change on the message body in order for the web service call to succeed.
Currently, the staff responsible for this part of the system has to:
- track the XML data down in a database for the failed web service call
- look over the XML to identify the bad data
- change the XML by hand
- re-send the XML to the correct web service URL using a windows client on their local machines.
They spend up to 75% of their time fixing these type of web service failure scenarios. This is because of:
- the high rate of messages generated by our system
- the high rate of primary key “unavailability” on the web service side.
- the XML for a given message can be quite large, and the two pieces of data that might have to change in order for the message to have the highest chance of succeeding are: - primary key value
- transaction type (this is an insert or update directive we give to their database via the XML)
Suffice to say, the current process is messy, error-prone and time-consuming.
Returning to the UI, the user can click on the “Edit and Resend” button, where they have the option to resend the message with no changes, or to update the primary key and/or Transaction Type value to something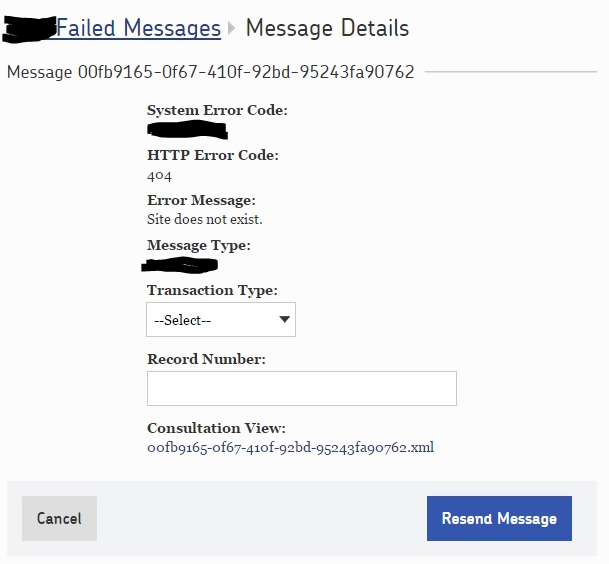 ](GHOST_URL/content/images/2015/07/editandresendmessage1.png)
](GHOST_URL/content/images/2015/07/editandresendmessage1.png)
Here you can see that there are two things we can change about the data on the message:
- Transaction Type: This is either an “insert” or an “update” value to be used on the web service’s back-end to determine what database operation to perform.
- Record Number: the Record Number is the primary key value. The user would enter an integer they THINK would work here.
When the user clicks “Resend Message” we send a ResendMessage command that when handled:
- looks up the XML based on the MessageId (aka, the xml file name is “[MessageId].xml”) and reads it from disk into memory.
- replaces the XML with the two pieces of information that could have been changed coming from the UI (or does nothing if no data needs to change)
- resends the message through the NServiceBus pipeline that invokes the web service.
If it fails, the message ends back up in the failed messages dashboard, where the user again tries to fix the message by changing the Transaction Type and/or Record Number to what they THINK will succeed.
In Conclusion
Our solution ended up being a message retrying mechanism of our own, with the caveat that we get to change some data on the message before we retry it. Although we had to write code to support it, it’s a huge improvement over what the staff responsible for this part of the system has to go through now in order to handle these web service failures. What we’ve done for them is:
- removed the manual intervention of them finding out what went wrong
- tracking down the XML on disk
- eyeballing the XML figuring out what data needs to change
- making the change by hand in the XML
- manually re-sending the XML directly to the web service from a windows app running on their local machine
All of this is handled for them in the system now, via a functional UI in which they can monitor the failure, change the data, and resend the message to the web service.Although we’ve turned off retries for the send endpoint, we’re still involving NServiceBus in the parts of the system where it make sense.
So their process has gone from this:

to this:

Happy integrations!